Porter 


Scalable and durable data imports for publishing and consuming APIs
Porter is the all-purpose PHP data importer. She fetches data from anywhere and serves it as a single record or an iterable record collection, encouraging processing one record at a time instead of loading full data sets into memory at once. Her durability feature provides automatic, transparent recovery from intermittent network connectivity errors by default.
Porter's interface trichotomy of providers, resources and connectors maps well to APIs. For example, a typical API such as GitHub would define the provider as GitHub, a resource as GetUser or ListRepositories and the connector could be HttpConnector.
Porter provides a dual API for synchronous and asynchronous imports, both of which are concurrency safe, so multiple imports can be paused and resumed simultaneously. Asynchronous mode allows large scale imports across multiple connections to work at maximum efficiency without waiting for each network call to complete.
Porter network quick links



Contents
- Benefits
- Quick start
- About this manual
- Usage
- Porter's API
- Overview
- Import specifications
- Record collections
- Asynchronous
- Transformers
- Filtering
- Durability
- Caching
- Architecture
- Providers
- Resources
- Connectors
- Requirements
- Limitations
- Testing
- Contributing
- License
Benefits
- Defines a formal structure for data import APIs: providers represent one or more resources that fetch data from connectors.
- Provides efficient data processing interfaces to handle large data sets one record at a time, via iterators, which can be implemented using generators.
- Asynchronous imports offer highly efficient CPU-bound data processing for large scale imports across multiple connections concurrently.
- Protects against intermittent network failures with durability features.
- Offers post-import transformations, such as filtering and mapping, to transform third-party into data useful for first-party applications.
- Supports PSR-6 caching, at the connector level, for each fetch operation.
- Joins two or more linked data sets together using sub-imports automatically.
Quick start
To get started quickly consuming an existing Porter provider, try our quick start guide. For a more thorough introduction continue reading.
About this manual
Those wishing to consume a Porter provider create one instance of Porter for their application and an instance of ImportSpecification for each data import they wish to perform. Those publishing providers must implement Provider and ProviderResource.
The first half of this manual covers Porter's main API for consuming data services. The second half covers architecture, interface and implementation details for publishing data services. There's an intermission in-between so you'll know where the separation is!
Text marked as inline code denotes literal code, as it would appear in a PHP file. For example, Porter refers specifically to the class of the same name within this library, whereas Porter refers to this project as a whole.
Porter has a dual API for the synchronous and asynchronous workflow dichotomy. Almost every Porter feature has an asynchronous equivalent. You will need to choose which you prefer to use. Most examples in this manual are for the synchronous API, for brevity and simplicity, but the asynchronous version will invariably be similar. Working synchronously may be easier when getting started but you are encouraged to use the async API if you are able, to reap its benefits.
Usage
Creating the container
Create a new Porter instance—we'll usually only need one per application. Porter's constructor requires a PSR-11 compatible ContainerInterface that acts as a repository of providers.
When integrating Porter into a typical MVC framework application, we'll usually have a service locator or DI container implementing this interface already. We can simply inject the entire container into Porter, although it's best practice to create a separate container just for Porter's providers.
Without a framework, pick any PSR-11 compatible library and inject an instance of its container class. We could even write our own container since the interface is easy to implement, but using an existing library is beneficial, particularly since most support lazy-loading of services. If you're not sure which to use, Joomla DI is fairly lightweight and straightforward.
Registering providers
Configure the container by registering one or more Porter providers. In this example we'll add the ECB provider for foreign exchange rates. Most provider libraries will export just one provider class; in this case it's EuropeanCentralBankProvider. We could add the provider to the container by writing something similar to $container->set(EuropeanCentralBankProvider::class, new EuropeanCentralBankProvider), but consult the manual for your particular container implementation for the exact syntax.
It is recommended to use the provider's class name as the container service name, as in the example in the previous paragraph. Porter will retrieve the service matching the provider's class name by default, so this reduces friction when getting started. If we use a different service name, it will need to be configured later in the ImportSpecification by calling setProviderName().
Importing data
Porter's import method accepts an ImportSpecification that describes which data should be imported and how the data should be transformed. To import DailyForexRates without applying any transformations we can write the following.
$records = $porter->import(new ImportSpecification(new DailyForexRates));
Calling import() returns an instance of PorterRecords or CountablePorterRecords, which both implement Iterator, allowing each record in the collection to be enumerated using foreach as in the following example.
foreach ($records as $record) {
// Insert breakpoint or var_dump($record) here to examine each record.
}
Porter's API
Porter's simple API comprises data import methods that must always be used to begin imports, instead of calling methods directly on providers or resources, in order to take advantage of Porter's features correctly.
Porter provides just two public methods for synchronous data import. These are the methods to be most familiar with, where the life of a data import operation begins.
import(ImportSpecification): PorterRecords|CountablePorterRecords– Imports one or more records from the resource contained in the specified import specification. If the total size of the collection is known, the record collection may implementCountable.importOne(ImportSpecification): ?array– Imports one record from the resource contained in the specified import specification. If more than one record is imported,ImportExceptionis thrown. Use this when a provider just returns a single record.
Porter's asynchronous API mirrors the synchronous one with similar method names but different signatures.
importAsync(AsyncImportSpecification): AsyncPorterRecords|CountableAsyncPorterRecords– Imports one or more records asynchronously from the resource contained in the specified asynchronous import specification.importOneAsync(AsyncImportSpecification): Promise<array>– Imports one record from the resource contained in the specified asynchronous import specification.
Overview
The following data flow diagram gives a high level overview of Porter's main interfaces and the data flows between them when importing data. Note that we use the term resource for brevity, but the interface is actually called ProviderResource, because resource is a reserved word in PHP.
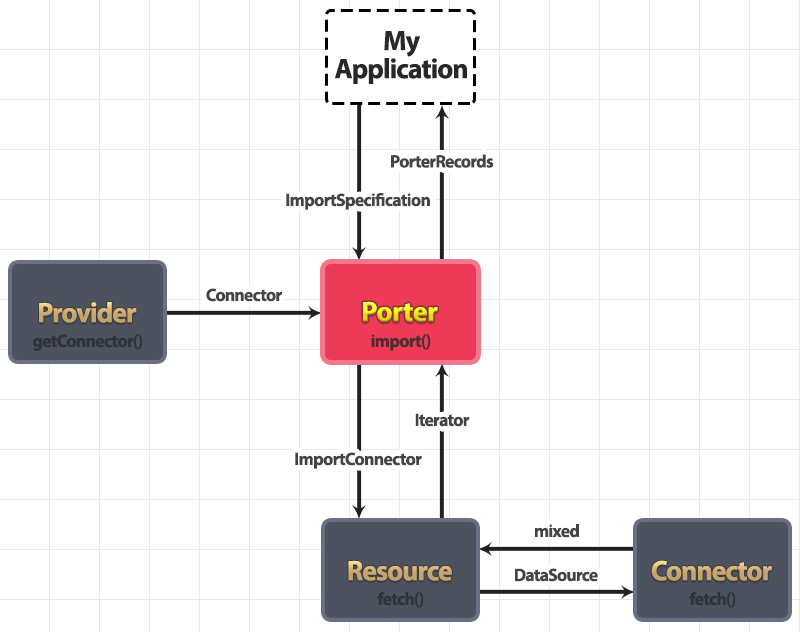
Our application calls Porter::import() with an ImportSpecification and receives PorterRecords back. Everything else happens internally so we don't need to worry about it unless writing custom providers, resources or connectors.
Import specifications
Import specifications specify what to import, how it should be transformed and whether to use caching. In synchronous code, create an new instance of ImportSpecification and pass a ProviderResource that specifies the resource we want to import. In Asynchronous code, create AsyncImportSpecification instead.
Options may be configured using the methods below.
setProviderName(string)– Sets the provider service name.addTransformer(Transformer)– Adds a transformer to the end of the transformation queue. In async code, passAsyncTransformerinstead.addTransformers(Transformer[])– Adds one or more transformers to the end of the transformation queue.setContext(mixed)– Specifies user-defined data to be passed to transformers.enableCache()– Enables caching. Requires aCachingConnector.setMaxFetchAttempts(int)– Sets the maximum number of fetch attempts per connection before failure is considered permanent.setFetchExceptionHandler(FetchExceptionHandler)– Sets the exception handler invoked each time a fetch attempt fails.setThrottle(Throttle)– Sets the asynchronous connection throttle, invoked each time a connector fetches data. Applies toAsyncImportSpecificationonly.
Record collections
Record collections are Iterators, guaranteeing imported data is enumerable using foreach. Each record of the collection is the familiar and flexible array type, allowing us to present structured or flat data, such as JSON, XML or CSV, as an array.
Details
Record collections may be Countable, depending on whether the imported data was countable and whether any destructive operations were performed after import. Filtering is a destructive operation since it may remove records and therefore the count reported by a ProviderResource would no longer be accurate. It is the responsibility of the resource to supply the total number of records in its collection by returning an iterator that implements Countable, such as ArrayIterator, or more commonly, CountableProviderRecords. When a countable iterator is used, Porter returns CountablePorterRecords, provided no destructive operations were performed.
Record collections are composed by Porter using the decorator pattern. If provider data is not modified, PorterRecords will decorate the ProviderRecords returned from a ProviderResource. That is, PorterRecords has a pointer back to the previous collection, which could be written as: PorterRecords → ProviderRecords. If a filter was applied, the collection stack would be PorterRecords → FilteredRecords → ProviderRecords. Normally this is an unimportant detail but can sometimes be useful for debugging.
The stack of record collection types informs us of the transformations a collection has undergone and each type holds a pointer to relevant objects that participated in the transformation. For example, PorterRecords holds a reference to the ImportSpecification that was used to create it and can be accessed using PorterRecords::getSpecification.
Metadata
Since record collections are just objects, it is possible to define derived types that implement custom fields to expose additional metadata in addition to the iterated data. Collections are very good at representing a repeating series of data but some APIs send additional non-repeating data which we can expose as metadata. However, if the data is not repeating at all, it should be treated as a single record rather than metadata.
The result of a successful Porter::import call is always an instance of PorterRecords or CountablePorterRecords, depending on whether the number of records is known. If we need to access methods of the original collection, returned by the provider, we can call findFirstCollection() on the collection. For an example, see CurrencyRecords of the European Central Bank Provider and its associated test case.
Asynchronous
The asynchronous API, introduced in version 5, is built on top of the fully programmable asynchronous framework, Amp. The synchronous API is not compatible with the asynchronous API so one must decide which to use. In general, the asynchronous API should be preferred for new projects because async can do everything sync can do, including emulating synchronous behaviour, but sync code cannot behave asynchronously without significant refactoring.
We must be inside the async event loop to begin programming asynchronously. Let's illustrate how to rewrite the earlier example asynchronously.
\Amp\Loop::run(function (): \Generator {
$records = $porter->importAsync(new AsyncImportSpecification(new DailyForexRates));
while (yield $records->advance()) {
$record = $records->current();
// Insert breakpoint or var_dump($record) here to examine each record.
}
});
We would not usually code directly inside the event loop in a real application, however we always need to create the event loop somewhere, even if it just calls a service method in our application which delegates to other objects. To pass asynchronous data through layers of abstraction, our application's methods must return Promises that wrap the data they would normally return directly in a synchronous application. For example, a method returning string would instead return Promise<string>, that is, a promise that returns a string.
Programming asynchronously requires an understanding of Amp, the async framework. Further details can be found in the official Amp documentation.
Throttling
The asynchronous import model is very powerful because it changes our application's performance model from I/O-bound, limited by the speed of the network, to CPU-bound, limited by the speed of the CPU. In the traditional synchronous model, each import operation must wait for the previous to complete before the next begins, meaning the total import time depends on how long it takes each import's network I/O to finish. In the async model, since we send many requests concurrently without waiting for the previous to complete, on average each import operation only takes as long as our CPU takes to process it, since we are busy processing another import during network latency (except during the initial "spin-up").
Synchronously, we seldom trip protection measures even for high volume imports, however the naïve approach to asynchronous imports is often fraught with perils. If we import 10,000 HTTP resources at once, one of two things usually happens: either we run out of PHP memory and the process terminates prematurely or the HTTP server rejects us after sending too many requests in a short period. The solution is throttling.
Async Throttle is a library included with Porter to throttle asynchronous imports. The throttle works by preventing additional operations starting when too many are executing concurrently, based on user-defined limits. By default, NullThrottle is assigned, which does not throttle connections. DualThrottle can be used to set two independent connection rate limits: the maximum number of connections per second and the maximum number of concurrent connections. A DualThrottle can be assigned by modifying the import specification as follows.
(new AsyncImportSpecification)->setThrottle(new DualThrottle)
Transformers
Transformers manipulate imported data. Transforming data is useful because third-party data seldom arrives in a format that looks exactly as we want. Transformers are added to the transformation queue of an ImportSpecification by calling its addTransformer method and are executed in the order they are added.
Porter includes one transformer, FilterTransformer, that removes records from the collection based on a predicate. For more information, see filtering. More powerful data transformations can be designed with MappingTransformer. More transformers may be available from Porter transformers.
Writing a transformer
Transformers implement the Transformer and/or AsyncTransformer interfaces that define one or more of the following methods.
public function transform(RecordCollection $records, mixed $context): RecordCollection;
public function transformAsync(AsyncRecordCollection $records, mixed $context): AsyncRecordCollection;
When transform() or transformAsync() is called the transformer may iterate each record and change it in any way, including removing or inserting additional records. The record collection must be returned by the method, whether or not changes were made.
Transformers should also implement the __clone magic method if the they store any object state, in order to facilitate deep copy when Porter clones the owning ImportSpecification during import.
Filtering
Filtering provides a way to remove some records. For each record, if the specified predicate function returns false (or a falsy value), the record will be removed, otherwise the record will be kept. The predicate receives the current record as an array as its first parameter and context as its second parameter.
In general we would like to avoid filtering because it is inefficient to import data and then immediately remove some of it, but some immature APIs do not provide a way to reduce the data set on the server, so filtering on the client is the only alternative. Filtering also invalidates the record count reported by some resources, meaning we no longer know how many records are in the collection before iteration.
Example
The following example filters out any records that do not have an id field present.
$records = $porter->import(
(new ImportSpecification(new MyResource))
->addTransformer(
new FilterTransformer(static function (array $record) {
return array_key_exists('id', $record);
})
)
);
Durability
Porter automatically retries connections when an exception occurs during Connector::fetch. This helps mitigate intermittent network conditions that cause temporary data fetch failures. The number of retry attempts can be configured by calling the setMaxFetchAttempts method of an ImportSpecification.
The default exception handler, ExponentialSleepFetchExceptionHandler, causes a failed fetch to pause the entire program for a series of increasing delays, doubling each time. Given that the default number of retry attempts is five, the exception handler may be called up to four times, delaying each retry attempt for ~0.1, ~0.2, ~0.4, and finally, ~0.8 seconds. After the fifth and final failure, FailingTooHardException is thrown.
The exception handler can be changed by calling setFetchExceptionHandler. For example, the following code changes the initial retry delay to one second.
$specification->setFetchExceptionHandler(new ExponentialSleepFetchExceptionHandler(1000000));
Durability only applies when connectors throw a recoverable exception type derived from RecoverableConnectorException. If an unexpected exception occurs the fetch attempt will be aborted. For more information, see implementing connector durability. Exception handlers receive the thrown exception as their first argument. An exception handler can inspect the recoverable exception and throw its own exception if it decides the exception should be treated as fatal instead of recoverable.
Caching
Any connector can be wrapped in a CachingConnector to provide PSR-6 caching facilities to the base connector. Porter ships with one cache implementation, MemoryCache, which caches fetched data in memory, but this can be substituted for any other PSR-6 cache implementation. The CachingConnector caches raw responses for each unique request, where uniqueness is determined by DataSource::computeHash.
Remember that whilst using a CachingConnector enables caching, caching must also be enabled on a per-import basis by calling ImportSpecification::enableCache().
Note that Caching is not yet supported for asynchronous imports.
Example
The follow example enables connector caching.
$records = $porter->import(
(new ImportSpecification(new MyResource))
->enableCache()
);
INTERMISSION
☕️
Congratulations! We have covered everything needed to use Porter.
The rest of this readme is for those wishing to go deeper. Continue when you're ready to learn how to write providers, resources and connectors.
Architecture
The following UML class diagram shows a partial architectural overview illustrating Porter's main components and how they are related. Asynchronous implementation details are mostly omitted since they mirror the synchronous system. [enlarge]
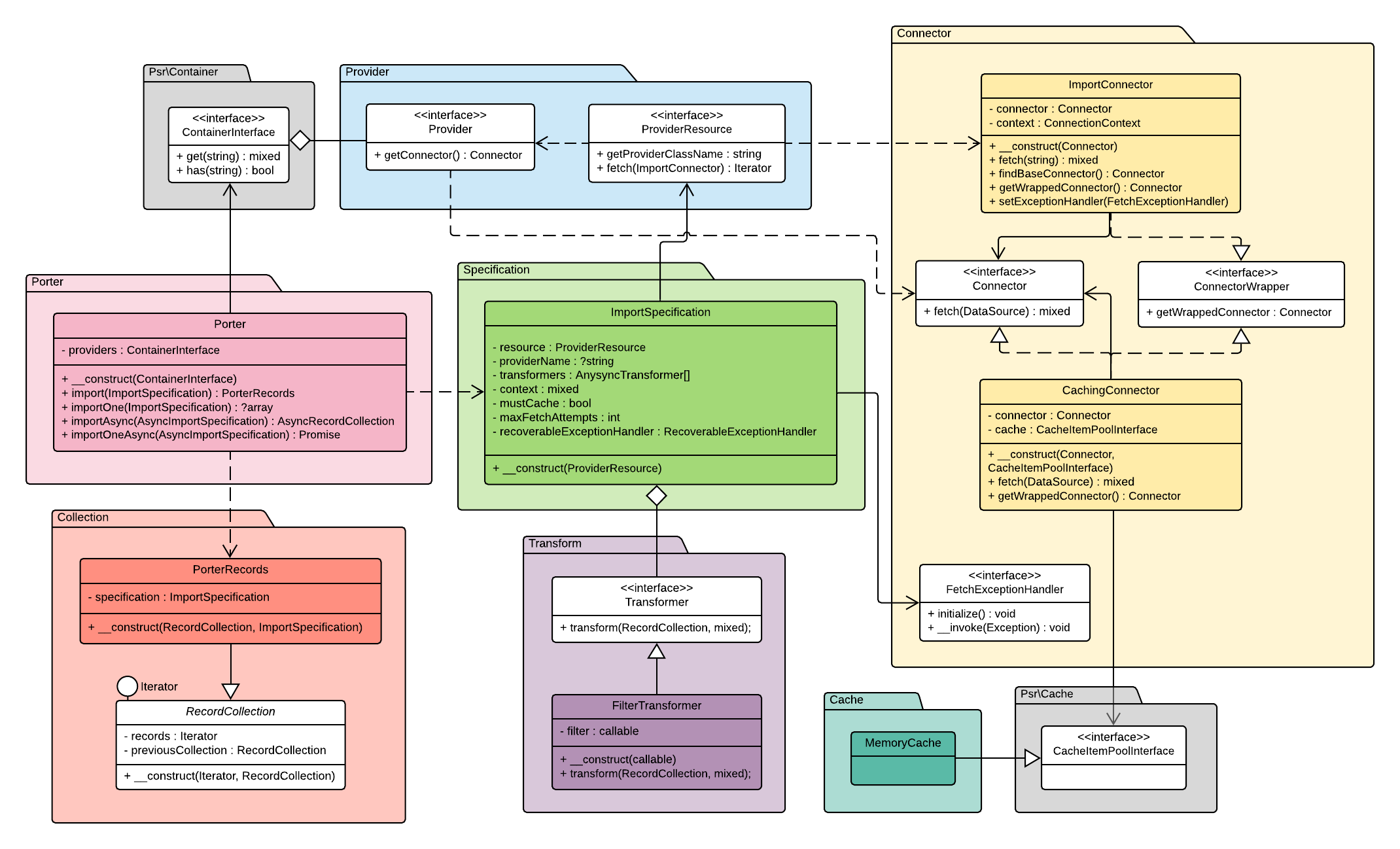
Providers
Providers supply their ProviderResource objects with a Connector. The provider must ensure it supplies a connector of the correct type for accessing its service's resources. A provider implements Provider that defines one method with the following signature.
public function getConnector() : Connector;
A provider does not know how many resources it has nor maintains a list of such resources and neither does any other part of Porter. That is, a resource class can be created at any time and claim to belong to a given provider without any formal registration.
Writing a provider
Providers must implement the Provider interface and supply a valid connector when getConnector is called. From Porter's perspective, writing a provider often requires little more than supplying the correct type hint when storing a connector instance, but we can embellish the class with any other features we may want. For HTTP service providers, it is common to add a base URL constant and some static methods to compose URLs, reducing code duplication in its resources.
Implementation example
In the following example we create a provider that only accepts HttpConnector instances. We also create a default connector in case one is not supplied. Note it is not always possible to create a default connector and it is perfectly valid to insist the caller supplies a connector.
final class MyProvider implements Provider
{
private $connector;
public function __construct(Connector $connector = null)
{
$this->connector = $connector ?: new HttpConnector;
}
public function getConnector(): Connector
{
return $this->connector;
}
}
Resources
Resources fetch data using the supplied connector and format it as a collection of arrays. A resource implements ProviderResource that defines the following three methods.
public function getProviderClassName(): string;
public function fetch(ImportConnector $connector): \Iterator;
A resource supplies the class name of the provider it expects a connector from when getProviderClassName() is called.
When fetch() is called it is passed the connector from which data must be fetched. The resource must ensure data is formatted as an iterator of array values whilst remaining as true to the original format as possible; that is, we must avoid renaming or restructuring data because it is the caller's prerogative to perform data customization if desired. The recommended way to return an iterator is to use yield to implicitly return a Generator, which has the added benefit of processing one record at a time.
The fetch method receives an ImportConnector, which is a runtime wrapper for the underlying connector supplied by the provider. This wrapper is used to isolate the connector's state from the rest of the application. Since PHP doesn't have native immutability support, working with cloned state is the only way we can guarantee unexpected changes do not occur once an import has started. This means it's safe to import one resource, make changes to the connector's settings and then start another import before the first has completed. Providers can also safely make changes to the underlying connector by calling getWrappedConnector(), because the wrapped connector is cloned as soon as ImportConnector is constructed.
Providing immutability via cloning is an important concept because resources are often implemented using generators, which implies delayed code execution. Multiple fetches can be started with different settings, but execute in a different order some time later when they're finally enumerated. This issue will become even more pertinent when Porter supports asynchronous fetches, enabling multiple fetches to execute concurrently. However, we don't need to worry about this implementation detail unless writing a connector ourselves.
Writing a resource
Resources must implement the ProviderResource interface. getProviderClassName() usually returns a hard-coded provider class name and fetch() must always return an iterator of array values.
In this contrived example that uses dummy data and ignores the connector, suppose we want to return the numeric series one to three: the following implementation would be invalid because it returns an iterator of integer values instead of an iterator of array values.
public function fetch(ImportConnector $connector): \Iterator
{
return new ArrayIterator(range(1, 3)); // Invalid return type.
}
Either of the following fetch() implementations would be valid.
public function fetch(ImportConnector $connector): \Iterator
{
foreach (range(1, 3) as $number) {
yield [$number];
}
}
Since the total number of records is known, the iterator can be wrapped in CountableProviderRecords to enrich the caller with this information.
public function fetch(ImportConnector $connector): \Iterator
{
$series = function ($limit) {
foreach (range(1, $limit) as $number) {
yield [$number];
}
};
return new CountableProviderRecords($series($count = 3), $count, $this);
}
Implementation example
In the following example we create a resource that receives a connector from MyProvider and uses it to retrieve data from a hard-coded URL. We expect the data to be JSON encoded so we decode it into an array and use yield to return it as a single-item iterator.
class MyResource implements ProviderResource, SingleRecordResource
{
private const URL = 'https://example.com';
public function getProviderClassName(): string
{
return MyProvider::class;
}
public function fetch(ImportConnector $connector): \Iterator
{
$data = $connector->fetch(self::URL);
yield json_decode($data, true);
}
}
If the data represents a repeating series, yield each record separately instead, as in the following example and remove the SingleRecordResource marker interface.
public function fetch(ImportConnector $connector): \Iterator
{
$data = $connector->fetch(self::URL);
foreach (json_decode($data, true) as $datum) {
yield $datum;
}
}
Exception handling
Unrecoverable exceptions will be thrown and can be caught as normal, but good connector implementations will wrap their connection attempts in a retry block and throw a RecoverableConnectorException. The only way to intercept a recoverable exception is by attaching a FetchExceptionHandler to the ImportConnector by calling its setExceptionHandler() method. Exception handlers cannot be used for flow control because their return values are ignored, so the main application of such handlers is to re-throw recoverable exceptions as non-recoverable exceptions.
Connectors
Connectors fetch remote data from a source specified at fetch time. Connectors for popular protocols are available from Porter connectors. It might be necessary to write a new connector if dealing with uncommon or currently unsupported protocols. Writing providers and resources is a common task that should be fairly easy but writing a connector is less common.
Writing a connector
A connector implements the Connector interface that defines one method with the following signature.
public function fetch(DataSource $source): mixed;
When fetch() is called the connector fetches data from the specified data source. Connectors may return data in any format that's convenient for resources to consume, but in general, such data should be as raw as possible and without modification. If multiple pieces of information are returned it is recommended to use a specialized object, like the HttpResponse returned by the HTTP connector that contains the response headers and body together.
Data sources
The DataSource interface must be implemented to supply the necessary parameters for a connector to locate a data source. For an HTTP connector, this might include URL, method, body and headers. For a database connector, this might be a SQL query.
DataSource specifies one method with the following signature.
public function computeHash(): string;
Data sources are required to return a unique hash for their state. If the state changes, the hash must change. If states are effectively equivalent, the hash must be the same. This is used by the cache system to determine whether the fetch operation has been seen before and thus can be served from the cache rather than fetching fresh data again.
It is important to define a canonical order for hashed inputs such that identical state presented in different orders does not create different hash values. For example, we might sort HTTP headers alphabetically before hashing because header order is not significant and reordering headers should not produce different output.
Durability
To support Porter's durability features a connector may throw a subclass of RecoverableConnectorException to signal that the fetch operation can be retried. Execution will halt as normal if any other exception type is thrown. It is recommended to throw a recoverable exception type when the fetch operation is idempotent.
Requirements
Limitations
Current limitations that may affect some users and should be addressed in the near future.
- No end-to-end data steaming interface.
- Caching does not support asynchronous imports.
- Sub-imports do not support async.
- No import rate throttle for synchronous imports.
Testing
Porter is fully unit and mutation tested.
- Run unit tests with the
composer testcommand. - Run mutation tests with the
composer mutationcommand.
Contributing
Everyone is welcome to contribute anything, from ideas and issues to code and documentation!
License
Porter is published under the open source GNU Lesser General Public License v3.0. However, the original Porter character and artwork is copyright © 2019 Bilge and may not be reproduced or modified without express written permission.
Quick links




![[BC-BREAK] scriptfusion/retry 1.1.2](https://avatars.githubusercontent.com/u/632452?v=4)

 1k Dec 27, 2022
1k Dec 27, 2022
 610 Jan 2, 2023
610 Jan 2, 2023
 3.5k Jan 8, 2023
3.5k Jan 8, 2023
 75 May 6, 2021
75 May 6, 2021
 82 Nov 11, 2022
82 Nov 11, 2022
 629 Nov 20, 2022
629 Nov 20, 2022
 465 Dec 30, 2022
465 Dec 30, 2022
 430 Jan 5, 2023
430 Jan 5, 2023
 85 Nov 28, 2022
85 Nov 28, 2022
 62 Dec 27, 2021
62 Dec 27, 2021
 108 Jun 30, 2022
108 Jun 30, 2022
 370 Dec 29, 2022
370 Dec 29, 2022
 121 Jan 6, 2023
121 Jan 6, 2023
 5.6k Jan 3, 2023
5.6k Jan 3, 2023
 10 Nov 2, 2022
10 Nov 2, 2022
 596 Jan 6, 2023
596 Jan 6, 2023
 1 Jan 18, 2022
1 Jan 18, 2022
 56 Dec 12, 2022
56 Dec 12, 2022
 268 Dec 27, 2022
268 Dec 27, 2022
 4 Oct 31, 2022
4 Oct 31, 2022